|
|
|
|
|
|
|
 |
webwork 4
TEXTARC,
by W. Bradford Paley
 While digital technology allows us to experiment with new forms of literary creation, it also allows for new ways of exploring existing texts.
While digital technology allows us to experiment with new forms of literary creation, it also allows for new ways of exploring existing texts.
Bradford Paley's work is a case in point.
TextArc is an on-line application that gives the viewer the opportunity to reconsider well-known literary works, an original way of revising, or more precisely, of revisiting the classics. Usage is simple: the viewer chooses a text from a library of international works - from Shakespeare to Zola, through the Bible and the American Constitution; the text then goes through the TextArc grinder - taken apart, broken down and split up -, which preserves its single constituent unit: the word. Words are listed and counted, and some statistics are extracted from them. Up to this point, TextArc resembles many other tools of linguistic analysis. But this one goes further.
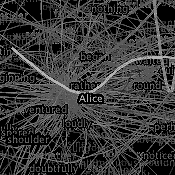
Visually, the work is formed of each of the sentences contained in the original text, displayed in 1-point type and arranged in an arc. Words then begin to appear, again and again, forming an almost compact and illegible mass. Each word, even if it is repeated in the text, appears only once, the frequency of its use being keyed to hue. The more it is used, the clearer it appears. Its position within the arc, which seems haphazard at first, is in fact calculated according to its initial position in the text. Thus, words scattered evenly throughout the literary work are central. Hovering over each word, coloured lines connect with its position in the arc, where the sentences that contain them are highlighted in green. In fact, the most central words are generally the main characters' names or surnames. To cite the two examples Paley features on his site, "Hamlet" is at the centre of the circle of Shakespeare's work, and "Alice" at that of Alice in Wonderland.
Another tool helps visualize occurrences. When activated, the "Show concordance" option displays a table listing word-counts. Obviously, the most commonly used words in each of the texts are grammatical elements (prepositions, articles, pronounced, verbs, adverbs), statistical information that won't further the analysis. Such words generally make up half the text, are not representative of the author or of his or her style, and bring nothing to the meaning of the work.
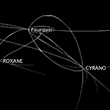
Yet the first terms to reveal the author's universe are often frequently occurring common nouns. Thus, in Proust's À l'ombre des jeunes filles en fleurs, the third most frequently used term is "temps" ("time"), which appears 83 times in the first part of the book. Similarly, in Cyrano de Bergerac, it is "nez" ("nose") that often crops up. With Molière, it isn't words that first grab one's attention, but certain exclamations: the "Ah", "Oh", and "Hé" that appear so frequently and reveal a writing style and the prevalence of theatrical effect.
Out of context, however, a word can have many interpretations. The option "Show association list" also reveals the frequency of associations and allows one to quickly make semantic connections. In Cyrano de Bergerac, words belonging to the repertoire of emotion - "coeur", "amour", "aimer" ("heart", "love", "to love") - are all associated with the character of Roxane.
Paley's application turns out to be an extremely interesting analytical tool that helps approach a text quickly and efficiently, grasping certain keys to a work through statistical information. It also helps make comparative analyses of several works or styles, or of a period, by exploring the richness of the vocabulary, or its evolution through the centuries, and thus draw a kind of portrait of language over a given period.
Besides mapping the text, the application is also designed to produce original readings. When the "Read" option is activated, an orange line snakes from one word to another, following the linearity of the original narrative, while the text runs simultaneously along the bottom of the screen, line after line. The words are then linked together (save for articles and grammatical elements) by this moving line that draws variously soft or abrupt curves and loops. Thus, each literary work has its own curve, and one could certainly go further to suggest that each author might have a type of curve, revelatory of style, of identity.
In any case, the long thread stretching out between words is a visual materialization of the text, its skeleton, emerging from the interactive space of TextArc, and is seconded by another, purple curve that represents the correlation between certain words, the visual representation of the associations mentioned previously. Thus, Paley calls upon a "powerful and underused resource, the process of human visualization". The reading of a work through TextArc is no longer a purely intellectual exercise, but more of an intuitive one. In fact, by thus relying on the reader's intuition, TextArc opens the way for a process of word association performed by the reader him- or herself, connecting information that parallels direct sight and visual memory.
In reappropriating the text's structure and content, subjecting it to this meticulous autopsy, and producing this interactive map of the work, TextArc relies on a process of unconscious linkage and intuitive understanding. The reading and intelligibility of a text via TextArc rests on the predominance of the intuitive over the rational. Not surprisingly, new connections are made, broadening a literary works field of possibilities
Cécile Petit

 top top
 back back
|
|
|
|
|
|